
Previously, the larger the AI mannequin, the higher the efficiency. Throughout OpenAI’s fashions for instance, parameters have grown by 1000x+ & efficiency has almost tripled.
| OpenAI Mannequin | Launch Date | Parameters, B | MMLU |
|---|---|---|---|
| GPT2 | 2/14/19 | 1.5 | 0.324 |
| GPT3 | 6/11/20 | 175 | 0.539 |
| GPT3.5 | 3/15/22 | 175 | 0.7 |
| GPT4 | 3/14/23 | 1760 | 0.864 |
However mannequin efficiency will quickly asymptote – not less than on this metric.
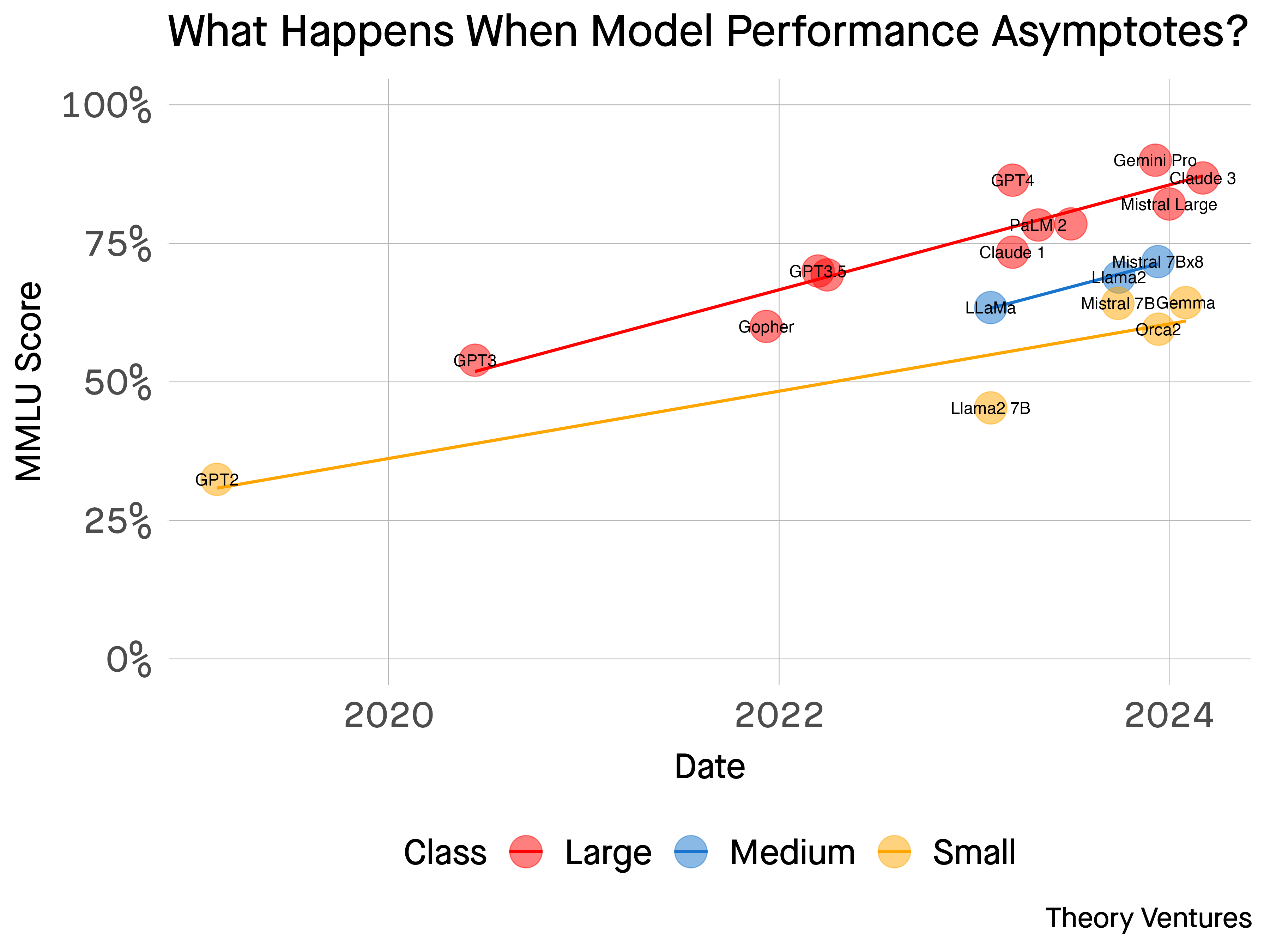
This can be a chart of many latest AI fashions’ efficiency based on a broadly accepted benchmark known as MMLU. 1 MMLU measures the efficiency of an AI mannequin in comparison with a highschool scholar.
I’ve categorized the fashions this fashion :
- Massive : > 100 billion parameters
- Medium : 15 to 100b parameters
- Small : < 15b parameters
Over time, the efficiency is converging quickly each throughout mannequin sizes & throughout the mannequin distributors.
What occurs when Fb’s open-source mannequin & Google’s closed-source mannequin that powers Google.com & OpenAI’s fashions that energy ChatGPT all work equally effectively?
Laptop scientists have been challenged distinguishing the relative efficiency of those fashions with many alternative exams. Customers can be hard-pressed to do higher.
At that time, the worth within the mannequin layer ought to collapse. If a freely obtainable open-source mannequin is simply nearly as good as a paid one, why not use the free one? And if a smaller, cheaper to function open-source mannequin is sort of nearly as good, why not use that one?
The fast development of AI has fueled a surge of curiosity within the fashions themselves. However fairly shortly, the infrastructure layer ought to commoditize, simply because it did within the cloud the place three distributors command 65% market share : Amazon Internet Companies, Azure, & Google Cloud Platform.
The functions & the developer tooling across the huge AI commodity brokers is the subsequent part of growth – the place product differentiation & distribution differentiate moderately than good, uncooked technical advances.2
1 MMLU measures 57 totally different duties together with math, historical past, pc science & different subjects. It’s one measure of many & it’s not good – like all benchmark. There are others together with the Elo system. Right here’s an overview of the variations.. Every benchmark grades the mannequin on a distinct spectrum : bias,
mathematical reasoning are two different examples.